Reliable uncertainty is not only about keeping the average error small. In many deployment settings, a few bad failures dominate the real cost. That is the motivation behind Spectral Conformal Risk Control, our new paper accepted to CVPR 2026. The goal is to preserve the distribution-free guarantees of conformal prediction while making the calibration target explicitly care about the tail of the loss distribution.
MS-COCO set size
3.39
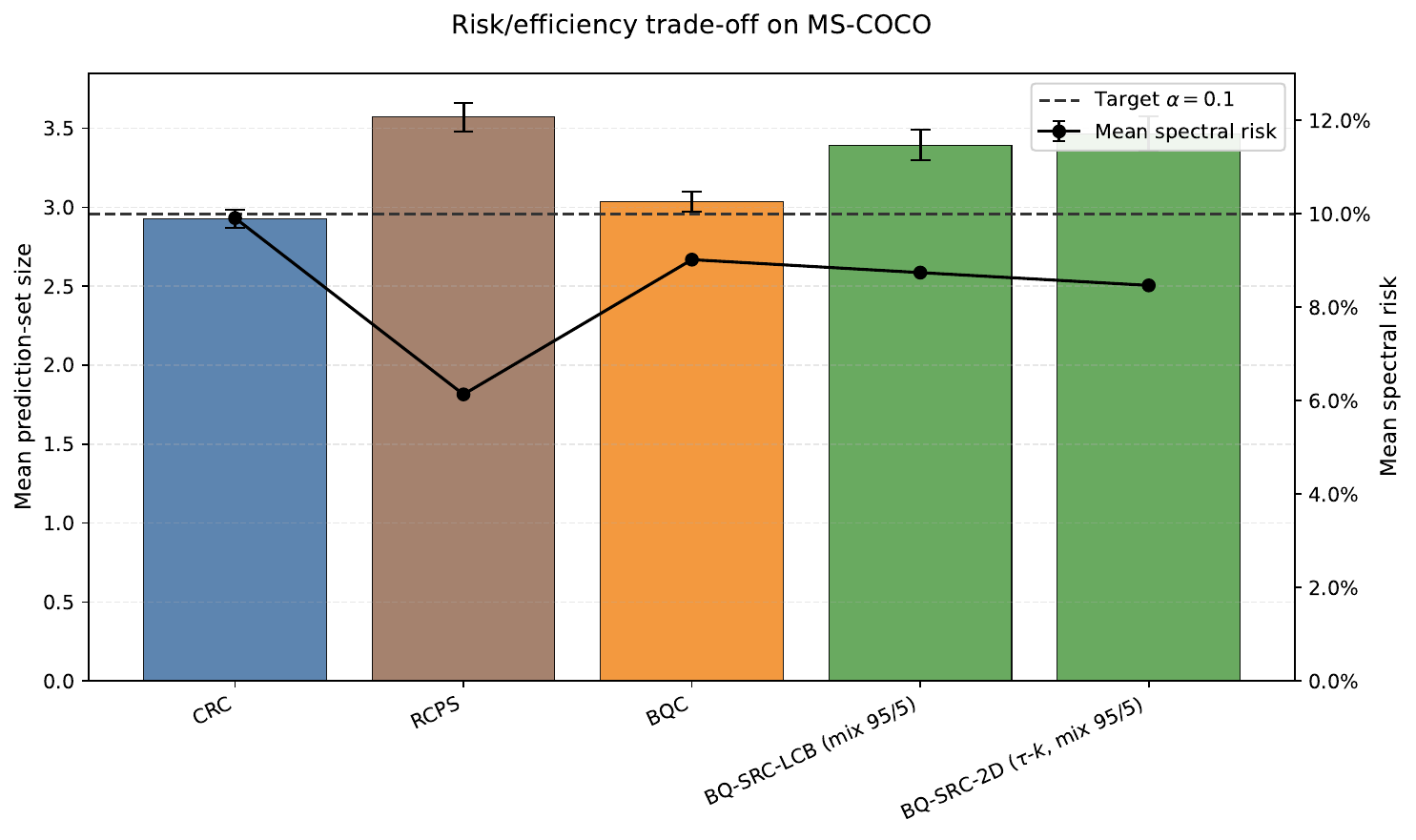
BQ-SRC-LCB mean prediction-set size, versus 3.57 for RCPS at matched validity.
Violation rate
0.60%
The two-parameter tau-k version stayed far below the 5 percent target on MS-COCO.
Monte Carlo tightening
~3x
Typical conservatism drops from about 0.0276 to 0.0096 when using the binomial LCB instead of DKW inflation.
Why this problem matters
Conformal prediction is appealing because it gives finite-sample, distribution-free guarantees. The problem is that the usual objectives mostly control mean risk. That is often too weak when the mistakes that matter are the rare, expensive ones: missing a tumor, dropping all relevant labels on a difficult image, or returning an overconfident segmentation in a safety-critical scene.
BQ-SRC moves the question from "is the average loss acceptable?" to "are we explicitly protecting against the part of the loss distribution we care about most?"
The core idea
Instead of integrating the loss quantile function against a uniform weighting, BQ-SRC uses a spectral density that can emphasize bad outcomes. That includes CVaR-style objectives and smoother mixtures like the 95/5 spectrum we used in several experiments. The method still works with the same high-level conformal workflow: keep the trained model fixed, reserve a calibration set, and certify a deployment parameter without making distributional assumptions beyond exchangeability.
Spectral risk instead of mean risk
We generalize from average-loss control to a family of risk measures that can place extra weight on the upper tail of the loss distribution.
Bayesian-quadrature view of calibration
The method inherits the Bayesian-quadrature lens on conformal prediction, but swaps the uniform integrator for a monotone, risk-averse one.
Black-box deployment
No retraining is required. BQ-SRC only needs calibrated access to the losses induced by a trained model and a chosen control parameter.
What changed technically
Encode the risk attitude directly.
We replace the usual uniform weighting with a monotone spectral density, which makes tail-heavy objectives such as CVaR natural special cases instead of afterthoughts.
Certify with a tighter Monte Carlo test.
Instead of relying on DKW inflation, we use an exact binomial lower confidence bound. In practice this noticeably reduces conservatism while keeping the same validity story.
Add joint tau-k control for multilabel prediction.
For MS-COCO-style multilabel tasks, we jointly tune a score threshold and a top-k fallback. That gives a better risk-efficiency frontier than pure threshold-only control.
Results I cared about most
The paper covers synthetic benchmarks, heteroskedastic regression, multilabel classification, semantic segmentation, closed-set classification, and zero-shot prediction. The broad pattern was consistent: once the objective explicitly cared about bad-tail behavior, we could keep finite-sample guarantees while getting a better deployment trade-off than mean-risk-only baselines.
Three experimental takeaways stood out:
- On synthetic spectral-risk benchmarks, tail-focused BQ-SRC variants reached zero violations in regimes where CRC failed often.
- On heteroskedastic regression, BQ-SRC accepted slightly longer intervals in exchange for much stronger control of tail miscoverage.
- On MS-COCO, the two BQ-SRC variants were the clearest practical win: better set-size efficiency than RCPS, with violations of 1.80 percent and 0.60 percent under a 5 percent target.
Beyond average-case uncertainty
One part I especially like is that the same framework extends cleanly to dense prediction. On ADE20K, the mix 95/5 spectrum reduced empirical risk from about 0.099 to 0.082 and improved coverage from 0.901 to 0.918 with only about 0.25 extra classes per pixel.

The same paper also includes closed-set and zero-shot classification experiments, plus a broad supplement covering temperature scaling, Monte Carlo budget sensitivity, grid-size robustness, and multivalid extensions. For me, that breadth matters: if a calibration method is going to be useful in practice, it needs to survive more than one carefully chosen benchmark.
Why I am excited about this paper
This project sits very close to the bigger theme I care about in reliable AI: not just whether a model is accurate on average, but whether it fails in a controlled way when the stakes are real. BQ-SRC gives a practical dial for that. It keeps the distribution-free flavor that makes conformal methods attractive, but it lets the deployment objective match the actual risk profile of the application.